Shashank Tripathi*, Alpár Cseke*, Sai Kumar Dwivedi, Arjun Lakshmipathy, Agniv Chatterjee, Michael J. Black, Dimitrios Tzionas
Computer Vision and Pattern Recognition (CVPR) 2025
Workshop on Generating Digital Twins from Images and Videos (gDT-IV @ ICCV) 2025 - Oral
Workshop on Human-Robot-Scene Interaction and Collaboration (HRSIC @ ICCV) 2025 - Oral
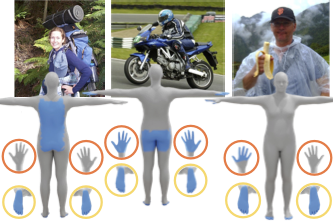
PICO recovers humans, objects, and their interactions (HOI) - all in 3D, from just a single internet image. To this end, we collect a new dataset of 3D contact correspondences, called PICO-db and a novel three-stage optimization framework PICO-fit.
Recovering 3D Human-Object Interaction (HOI) from single color images is challenging due to depth ambiguities, occlusions, and the huge variation in object shape and appearance. Thus, past work requires controlled settings such as known object shapes and contacts, and tackles only limited object classes. Instead, we need methods that generalize to natural images and novel object classes. We tackle this in two main ways: (1) We collect PICO-db, a new dataset of natural images uniquely paired with dense 3D contact on both body and object meshes. To this end, we use images from the recent DAMON dataset that are paired with contacts, but these contacts are only annotated on a canonical 3D body. In contrast, we seek contact labels on both the body and the object. To infer these given an image, we retrieve an appropriate 3D object mesh from a database by leveraging vision foundation models. Then, we project DAMON's body contact patches onto the object via a novel method needing only 2 clicks per patch. This minimal human input establishes rich contact correspondences between bodies and objects. (2) We exploit our new dataset of contact correspondences in a novel render-and-compare fitting method, called PICO-fit, to recover 3D body and object meshes in interaction. PICO-fit infers contact for the SMPL-X body, retrieves a likely 3D object mesh and contact from PICO-db for that object, and uses the contact to iteratively fit the 3D body and object meshes to image evidence via optimization. Uniquely, PICO-fit works well for many object categories that no existing method can tackle. This is crucial to enable HOI understanding to scale in the wild. Our data and code are available.
@inproceedings{cseke_tripathi_2025_pico,
title = {{PICO}: Reconstructing {3D} People In Contact with Objects},
author = {Cseke, Alp\'{a}r and Tripathi, Shashank and Dwivedi, Sai Kumar and
Lakshmipathy, Arjun and Chatterjee, Agniv and Black, Michael J. and Tzionas,
Dimitrios},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR)},
month = {June},
year = {2025},
}